Deep Dive into Kubernetes
I started learning K8S since I didn’t want to admit during the interview that I’m a DevOps engineer but had no idea what K8S was or how it operated. and as it sounds so nice on resume, wrote a blog post titled “Getting Started with Kubernetes.”
But now that I’ve developed and deployed a full-stack web application, I wanted to go further into the Kubernetes architecture to comprehend what truly transpires and who interacts with whom.
And I did.
Let’s start with simple architecture(I’m lying).

- User wants to deploy nginx pods with 3 replica and wrote a deployment in YAML.

For practical implementation, I’m using k3s
Then user ran a simple command to get the work done that is
kubectl apply -f nginx-deployment.ymlWithin few seconds the pods will be up and running.
- If we break the whole deployment in multiple commands, it will look like this
kubectl create deploy nginx-deployment --image=nginx
#create a deployment with single replicakubectl scale deploy nginx-deployment --replicas=3
#Now we have three replica for above deploymentkubectl expose deployment nginx-deployment --port=80
#expose the container on port 80


What happened behind the scene?
- User declares what he/she wants(image 1)and pass that to K8S using kubectl command. We all know that API-Server is the only component that can talk to user, master node other components and worker nodes.
- kubectl interacts with API-Server and generates a manifest(we can say a description of user wants).
- This manifest is written in ETCD(key-value database and single source of truth) by API-Server.
- API-Server got a deployment of nginx so it stores a deployment in ETCD.
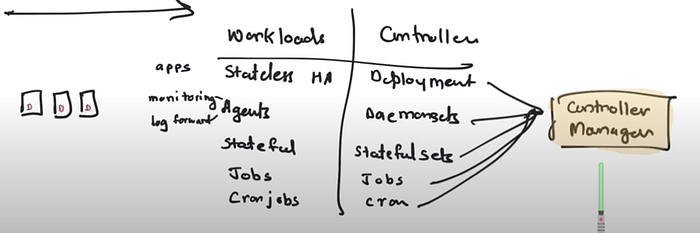
- As soon as there is something in ETCD, controller manager wakes up and respond according to the requirement. For deployment, a Deployment controller wakes up and check the requirement. It says replica is needed so, it’ll create a replica set(a bunch of item that goes into the pods) and goes to sleep. The ReplicaSet get stored in ETCD and the flow was [controller manager → API-Server → ETCD ].
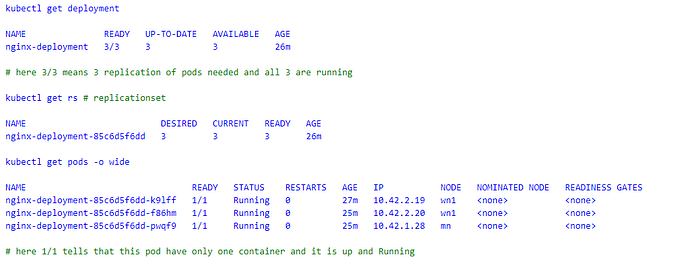
- Now, the controller responsible for replica take its turn and create 3 replicas(Image 4) of pod(just create the pods). The pods details get stored in ETCD.
- A ReplicaSet ensures that a specified number of pod replicas are running at any given time. However, a Deployment is a higher-level concept that manages ReplicaSets and provides declarative updates to Pods along with a lot of other useful features(Image 2).
- Schedular wakes up and see that there are pending pods without any nodes assigned. So, it will assign the nodes and goes to sleep.
- kubelet(on worker node) asks API-Server whether it has something for them? Now nodes has been assigned to pods kubelet will pull the image, networking and response back to API-Server that pods are running and API-Server writes the update to ETCD.
- As you can see everything is being written to ETCD from deployment to pods health.
- Note: All controller manager’s binaries are compiled in one.

What happens on Worker Node?
We understood the communication between different components of master node and also got to know kubelet and API-Server interacts with each other.
Kubelet → An agent that runs on each worker node in the cluster. It makes sure that containers are running in a Pod.
From definition we understood what it does but there is something that can be mistaken. Kubelet only starts the containers and let the container engine deal with other containers configuration such as network. As a result it can be possible that two pods in different nodes have the same IP.
Wait a minute, in above para you were talking about the container’s IP and suddenly move to pod’s IP?
As we know a pod can have multiple containers and a node can have multiple pods. But in general, a pod runs a single instance of your application that is a single container and the container’s IP become Pod’s IP. So, container’s IP equals to pod’s IP(Image 10).
For better understanding please check the below screenshots:

So how output of a pod with 2 containers looks like and in this case IP of pod will not equals to containers.

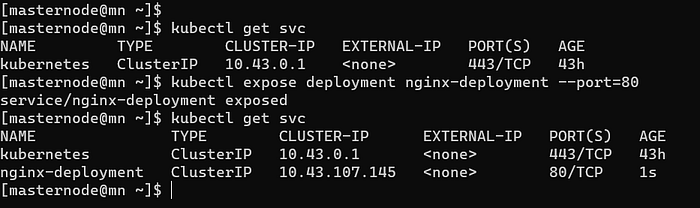
Exposing the nginx running on a set of Pods as a network service
Deployment, ReplicaSet and pods are done, we understood maximum of it. But we haven’t talked out the networking interface and we exposed the pods so that it can be curled on port 80(Image 5 and Image 6).
If a pod restarts or dies, its IP address may change since IP addresses are dynamic; however, how do other pods learn that they must now connect to a different IP address? Example:
One deployment is for a web application, the other is for a database, for instance. As soon as MySQL pod died, K8S launched a new one with a different IP, and the web application needed the IP of the database to connect to it. Now that our webapp cannot connect to the database, we risk losing our customers.
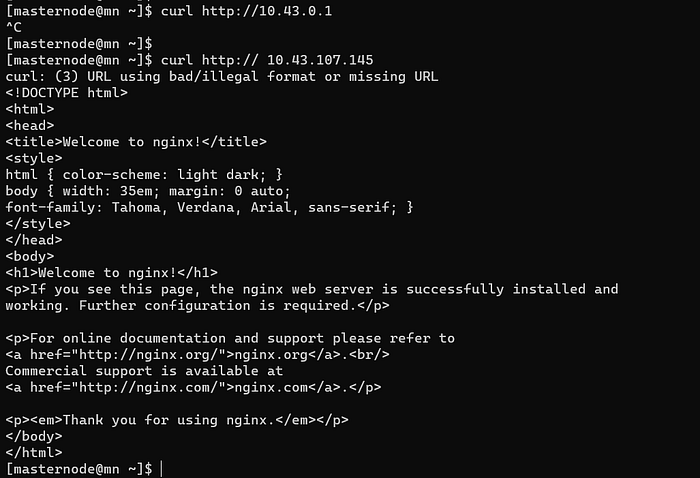
To resolve this we use service component. Service assign static IPs to the pods, hence whether under the hood pods IP get changed static IP will be the same and customer can use the webapp smoothly.
But how service component works? in above simple architecture(Image 1) it is not mentioned.
kube-proxy is a network proxy that runs on each node in your cluster, implementing part of the Kubernetes Service concept. kube-proxy maintains network rules on nodes. These network rules allow network communication to your Pods from network sessions inside or outside of your cluster.
It generates the IP tables rules that is where to redirect, forward the traffic.
# a simple example from Image 5
# curl 10.43.107.145 gives a beautiful output
# but the IP of pods are 10.42.2.*
# what kube-proxy did it created a route10.43.107.145:80 ------> 10.42.2.*:80
# forward incoming traffic to 10.42.2.*:80
# you can check the IP tables by
iptables -t nat -nxv (check documentation for more argument)
Note: Kubelet talks to kube-proxy and container engine.
What if I have to assign a different subnets other than the defaults one?
Each node have a subnet and kubenet picks up a IP and assign it to pod and put the pod on the bridge. To change the subnet and use kubenet component start kubelet with specified options on worker nodes but the existing running pods will not get affected. So we have to delete the pods. But in addition to choosing the subnet, route tables and IP tables needs to bee created manually which is very hectic tasks.
To deal with this CNI(Container Network Interface) is used. I haven’t went to more detail about this but you can check the official documentation for reference.
Till now, we have talked about Kubectl, master node components(API-Server, Controller manager, Schedular, ETCD), worker node components(Kubelet, kube-proxy, container engine, containers), and k8s components(deployment, replica, pods, service) which give a basic idea about the internals of k8s.
In next blog, I have talk about the Kubernetes cluster setup with kubeadm. Check it out.
Thank you for reading!!!
